监控相关
ZABBIX安装与使用
自动发现与自动注册
配置文件
分布式监控
zabbix_sender安装和使用
zabbix_get安装与使用
自定义监控
自动发现监控json
PERCONA插件
PERCONA多实例
日志监控
相关项目监控
监控MySQL
监控Haproxy
Fluentd日志监控
Grafana(可视化监控指标)
grafana地图插件
添加prometheus模板
开启HTTPS
添加zabbix插件
Grafana模板
正则表达式
Prometheus监控
安装与使用
Prometheus存储
服务发现
Prometheus标签
PromQL查询
PushGateway推送组件
AlertManager告警组件
告警规则rule
K8S监控(kube-state-metric/cadvisor)
探针监控(blackbox_exporter)
Node_export
Mysql_export
Redis-exporter
cloudeye-exporter【华为云监控】
RabbitMQ-exporter
K8S监控
本文档使用MrDoc发布
返回首页
-
+
安装与使用
2021年5月25日 10:50
admin
#下载主页 https://prometheus.io/download/ #安装SERVER wget https://github.com/prometheus/prometheus/releases/download/v2.27.1/prometheus-2.27.1.linux-amd64.tar.gz tar -zxvf prometheus-2.27.1.linux-amd64.tar.gz mv prometheus-2.27.1.linux-amd64/ /usr/local/prometheus cd /usr/local/prometheus ./prometheus --version  ####修改prometheus.yml文件 vim prometheus.yml #内容: ------------------------------------------------------------ global: scrape_interval: 15s #每15s采集一次数据 evaluation_interval: 15s #每15s做一次告警检测 alerting: #告警设置 alertmanagers: - static_configs: - targets: # - alertmanager:9093 rule_files: #告警规则设置 # - "first_rules.yml" #告警规则文件 # - "second_rules.yml" scrape_configs: #监控目标设置 - job_name: 'prometheus' #job名称 # metrics_path defaults to '/metrics' #采集信息url后缀 # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090'] #采集节点ip及端口 #启动SERVER cd /usr/local/prometheus ./prometheus #前台启动 nohup ./prometheus & #后台启动 #访问SERVER http://【SERVERIP】:9090/ 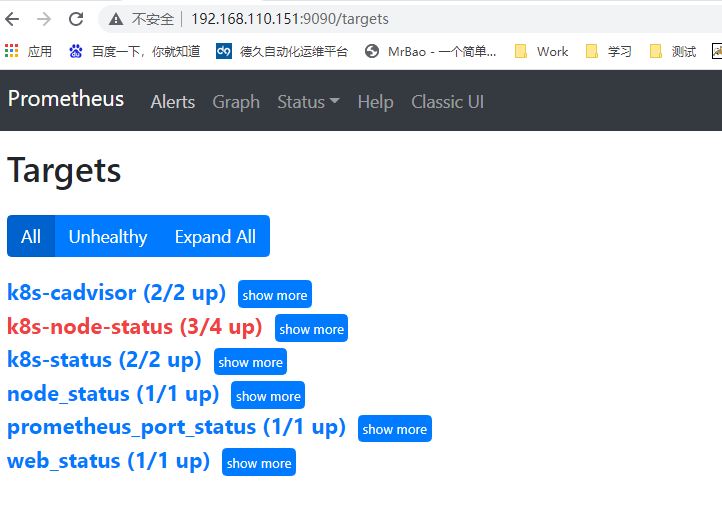 #SERVER启动参数 |参数名称|含义|备注 |--|--|-- |--version|显示应用的版本信息| |配置文件参数 |--config.file="prometheus.yml"|Prometheus配置文件路径| |WEB服务参数 |--web.listen-address="0.0.0.0:9090"|UI、API、遥测(telemetry)监听地址| |--web.read-timeout=5m|读取请求和关闭空闲连接的最大超时时间|默认值:5m |--web.max-connections=512|最大同时连接数|默认值:512 |--web.external-url=<URL>|可从外部访问普罗米修斯的URL|如果Prometheus存在反向代理时使用,用于生成相对或者绝对链接,返回到Prometheus本身,如果URL存在路径部分,它将用于给Prometheus服务的所有HTTP端点加前缀,如果省略,将自动派生相关的URL组件。 |--web.route-prefix=<path>|Web端点的内部路由|默认路径:--web.external-url |--web.user-assets=<path>|静态资产目录的路径|在/user路径下生效可用 |--web.enable-lifecycle|通过HTTP请求启用关闭(shutdown)和重载(reload)| |--web.enable-admin-api|启用管理员行为API端点| |--web.console.templates="consoles"|总线模板目录路径|在/consoles路径下生效可用 |--web.console.libraries="console_libraries"|总线库文件目录路径| |--web.page-title="Prometheus Time Series Collection and Processing Server"|Prometheus实例的文档标题| |--web.cors.origin=".*"|CORS来源的正则Regex,是完全锚定的|例如:'https?://(domain1|domain2).com' |数据存储参数 |--storage.tsdb.path="data/"|指标存储的根路径| |--storage.tsdb.retention=STORAGE.TSDB.RETENTION|[DEPRECATED]样例存储时间|此标签已经丢弃,用"storage.tsdb.retention.time"替代 |--storage.tsdb.retention.time=STORAGE.TSDB.RETENTION.TIME|存储时长,如果此参数设置了,会覆盖"storage.tsdb.retention"参数;如果设置了"storage.tsdb.retention" 或者"storage.tsdb.retention.size"参数,存储时间默认是15d(天),单位:y, w, d, h, m, s, ms| |--storage.tsdb.retention.size=STORAGE.TSDB.RETENTION.SIZE|[EXPERIMENTAL]试验性的。存储为块的最大字节数,需要使用一个单位,支持:B, KB, MB, GB,TB, PB, EB|此标签处于试验中,未来版本会改变 |--storage.tsdb.no-lockfile|不在data目录下创建锁文件| |--storage.tsdb.allow-overlapping-blocks|[EXPERIMENTAL]试验性的。允许重叠块,可以支持垂直压缩和垂直查询合并。| |--storage.tsdb.wal-compression|压缩tsdb的WAL|WAL(Write-ahead logging, 预写日志),WAL被分割成默认大小为128M的文件段(segment),之前版本默认大小是256M,文件段以数字命名,长度为8位的整形。WAL的写入单位是页(page),每页的大小为32KB,所以每个段大小必须是页的大小的整数倍。如果WAL一次性写入的页数超过一个段的空闲页数,就会创建一个新的文件段来保存这些页,从而确保一次性写入的页不会跨段存储。 |--storage.remote.flush-deadline=<duration>|关闭或者配置重载时刷新示例的等待时长| |--storage.remote.read-sample-limit=5e7|在单个查询中通过远程读取接口返回的最大样本总数。0表示无限制。对于流式响应类型,将忽略此限制。| |--storage.remote.read-concurrent-limit=10|最大并发远程读取调用数。0表示无限制。| |--storage.remote.read-max-bytes-in-frame=1048576|在封送处理之前,用于流式传输远程读取响应类型的单个帧中的最大字节数。请注意,客户机可能对帧大小也有限制。|默认情况下,protobuf建议使用1MB。 |告警规则相关参数 |--rules.alert.for-outage-tolerance=1h|允许prometheus中断以恢复“for”警报状态的最长时间。| |--rules.alert.for-grace-period=10m|警报和恢复的“for”状态之间的最短持续时间。这仅对配置的“for”时间大于宽限期的警报进行维护。| |--rules.alert.resend-delay=1m|向Alertmanager重新发送警报之前等待的最短时间。| |告警管理中心相关参数 |--alertmanager.notification-queue-capacity=10000|挂起的Alertmanager通知的队列容量。|默认值:10000 |--alertmanager.timeout=10s|发送告警到Alertmanager的超时时间|默认值:10s |数据查询参数 |--query.lookback-delta=5m|通过表达式解析和联合检索指标的最大反馈时间|默认值:5m |--query.timeout=2m|查询中止前可能需要的最长时间。|默认值:2m |--query.max-concurrency=20|并发(concurrently)执行查询的最大值| |--query.max-samples=50000000|单个查询可以加载到内存中的最大样本数。注意,如果查询试图将更多的样本加载到内存中,则会失败,因此这也限制了查询可以返回的样本数。|数量级:5千万 |日志信息参数 |--log.level=info|仅记录给定的日志级别及以上的信息|可选参数值:[debug, info, warn, error],其中之一 |--log.format=logfmt|日志信息输出格式|可选参数值:[logfmt, json],其中之一 --- #安装EXPORTER wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz tar -zxvf node_exporter-1.1.2.linux-amd64.tar.gz mkdir -p /usr/local/exporter/ mv node_exporter-1.1.2.linux-amd64 /usr/local/exporter/node_exporter #启动EXPORTER cd /usr/local/exporter/node_exporter ./node_exporter #前台启动 nohup ./node_exporter & #后台启动 ----------------------------------------------------------- --web.listen-address=":9100" #node_exporter监听的端口,默认是9100,若需要修改则通过此参数。 --web.telemetry-path="/metrics" #获取metric信息的url,默认是/metrics,若需要修改则通过此参数 --log.level="info" #设置日志级别 --log.format="logger:stderr" #设置打印日志的格式,若有自动化日志提取工具可以使用这个参数规范日志打印的格式 #启用textfile收集器(自定义指标) ####编写收集器 mkdir -p /var/lib/node_exporter/textfile_collector ####所有自定义生成的指标需要按照如下的方式进行存储,首先使用shell或者python脚本最终写入文件的格式需要如下: # HELP example_metric Metric read from /some/path/textfile/example.prom # TYPE example_metric untyped example_metric 1 ####收集器脚本范例 #!/bin/sh # Expose directory usage metrics, passed as an argument. # Usage: add this to crontab: # */5 * * * * prometheus directory-size.sh /var/lib/prometheus | sponge /var/lib/node_exporter/directory_size.prom echo "# HELP node_directory_size_bytes Disk space used by some directories" echo "# TYPE node_directory_size_bytes gauge" du --block-size=1 --summarize "$@" \ | sed -ne 's/\\/\\\\/;s/"/\\"/g;s/^\([0-9]\+\)\t\(.*\)$/node_directory_size_bytes{directory="\2"} \1/p' ####定时执行脚本 crontab -e #内容 */5 * * * * bash /var/lib/node_exporter/textfile_collector/printMetrics.sh > /var/lib/node_exporter/textfile_collector/metrics.prom ####启动 ./node_exporter --collector.textfile.directory /var/lib/node_exporter/textfile_collector 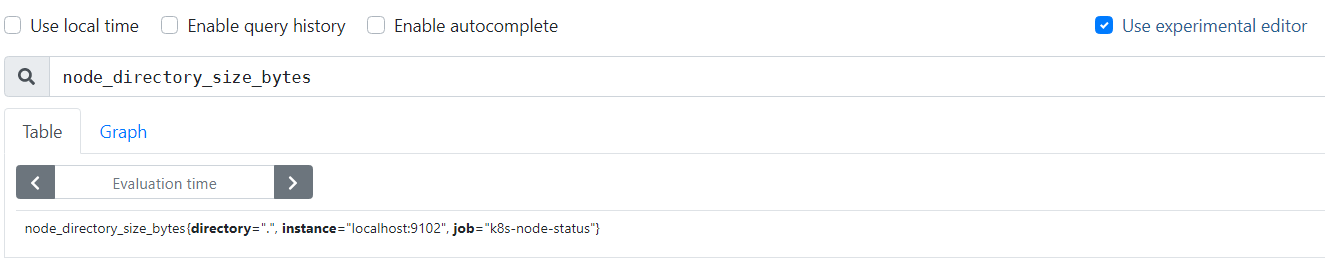 --- #启用systemd收集器 ./node_exporter --collector.systemd --collector.systemd.unit-whitelist="(docker|ssh|rsyslog).service" --- #检查配置 ./promtool check config prometheus.yml 
分享到: