容器相关
非root用户Docker与K8S
Containerd安装
Containerd常用命令
Docker
镜像创建
国内镜像仓库
容器创建(Dockerfile)
容器系统
docker配置
docker数据管理
docker网络管理
docker容器自启动
docker镜像加速
docker问题
搭建Portainer可视化界面
Docker Swarm
Swarm搭建Docker集群
Docker Compose
Docker Compose命令
Docker Compose模板
Docker Machine
Kubernetes常用命令
k8s部署(kubeadmin)
k8s高可用部署
MiniKube
k8s1.24部署(containerd)
k8s1.24部署(docker)
部署 Dashboard
Kuboard K8S管理台
k8s权限管理
k8s网络插件
私有仓密码镜像拉取
k8s集群管理
POD--基本单位
Pod模板
Pod生命周期
Pod健康检查
初始化容器(initContainer)
Deployment--Pod的管理
Deployment模板
Deployment升级与回滚
DaemonSet控制器
StatefulSet控制器(有状态)
JOB与CRONJOB
Service--发布服务
ingress-traefix
ingress-nginx
MetalLB
存储与配置
持久存储卷
配置存储卷
资源管理
标签、选择器与注解
资源预留
调度管理
自动扩容
Proxy API与API Server
Helm--K8S的包管理器
helm常用命令
自定义Chart
私有chart仓库
helm dashboard
K8S证书过期
K8S问题解决
Harbor安装
Harbor操作
Harbor问题
Harbor升级
Docker Registry安装
Docker Registry鉴权
Registry用Nginx代理SSL及鉴权
Docker Registry问题
Istio 服务网络
常用示例
Gateway【服务网关】
kiali 可视化页面
开启HTTPS
linkerd 服务网络
本文档使用MrDoc发布
返回首页
-
+
调度管理
2021年9月24日 15:23
admin
##限制注意: ####1、同时指定nodeSelector 和 nodeAffinity,pod必须都满足 ####2、nodeAffinity有多个nodeSelectorTerms ,pod只需满足一个 ####3、nodeSelectorTerms多个matchExpressions ,pod必须都满足 ####4、由于IgnoredDuringExecution,所以改变labels不会影响已经运行pod --- #节点调度 ##方式一:直接指定 apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] nodeName: work01 #直接指定pod调度到work01节点上 --- ##方式二:节点标签 ####先给节点打标签 kubectl label nodes work01 app=nginx ####创建pod的yaml文件 apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] nodeSelector: app: nginx #调度到标签为app:nginx的节点上 --- #亲和性调度 ##节点亲和性(基于标签指定法) ####先给节点打标签 kubectl label nodes work01 app=nginx,relase=state,version=1.12 ####创建pod的yaml文件 apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - {key: app, operator: In, values: [nginx,web]} - {key: relase, operator:NotIn, values:[test]} preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - {key:version operator: In, values:[1.12,1.13]} --- ##注意: ####1、requiredDuringScheduingIgnoredDuringExecution与requiredDuringScheduingRequiredDuringExecution的区别在于,后者Pod调度成功运行后,如果节点标签发生变化而不再满足条件,Pod将会驱逐出节点,而前者不会 ####2、requiredDuringSchedulingIgnoredDuringExecution为硬限制,preferredDuringSchedulingIgnoredDuringExecution为软限制。 --- ##Pod亲和性 ####注意:Pod的亲和性和反亲和性调度会涉及大量调度运算,会显著减慢在大型集群中的调度,不建议在大于几百哥节点的集群中使用它们 --- ####创建pod的yaml文件 apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] affinity: podAffinity: #亲和 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app, operator: In, values: [nginx,web]} - {key: relase, operator:NotIn, values:[test]} topologyKey:'Kubernetes.io/hostname' preferredDuringSchedulingIgnoredDuringExecutio: - weight: 1 podAffinityTerm: labelSelector: matchExpressions: - {key:version operator: In, values:[1.12,1.13]} topologyKey:'Kubernetes.io/hostname' --- ####以上示例设置: ####1、硬亲和条件,寻找app标签在[nginx,web]和relase寻找app标签在不在test中的Pod,硬亲和条件key标签在[1.12,1.13]中。 ####2、weight字段表示相对于其它软亲和条件的优先级,取值1~100,越大优先级越高 ####3、topologyKey:'Kubernetes.io/hostname',表示如果满足亲和性条件,则会将Pod调度到和已有Pod所在节点的ubernetes.io/hostname标签值相同的节点上,对于此示例,也就是说,会将该Pod调度到同一台机器上。 --- ##Pod反亲和性 ####创建pod的yaml文件 apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] affinity: podAntiAffinity: #反亲和 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app, operator: In, values: [nginx,web]} topologyKey:'Kubernetes.io/hostname' preferredDuringSchedulingIgnoredDuringExecutio: - weight: 1 podAntiAffinityTerm: labelSelector: matchExpressions: - {key:version operator: In, values:[1.12,1.13]} topologyKey:'Kubernetes.io/hostname' --- #污点 ##添加污点 kubectl taint node <节点名称> <污点名称>=<污点值>:<污点影响> ####污点影响: NoExecute: 不将Pod调度到具备该污点的机器上,如果Pod已经在某台机器上运行,且设置了NoExecute污点,则不能容忍该污点的Pod将会被驱逐。 NoSchedule: 不将Pod调度到具备该污点的机器上,对于已运行的Pod不会驱逐 PreNoSchedule: 不推荐将Pod调度到具备该污点的机器上 ##删除污点 kubectl taint node <节点名称> <污点名称>- ##查看污点 kubectl describe node <节点名称> #查看taint段内容 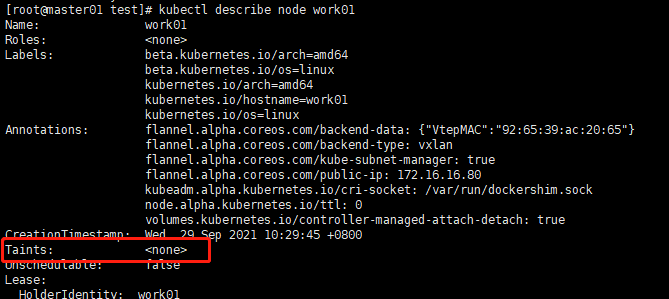 --- ##示例:开启master调度 #开启(删除污点) kubectl taint node master node-role.Kubernetes.io/master- #关闭(添加污点,使Pod不调度到此机上) kubectl taint node master node-role.Kubernetes.io/master="":NoSchedule --- #容忍度 ####注意:让Pod调度到具备污点的机器上,则必须要为Pod设置容忍度,让她能接受这些污点。 --- apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] tolerations: - key: "restart" operator: "Equal" value: "hourly" effect: "NoSchedule" - key: "isMaintain" operator: "Equal" value: "true" effect: "NoExecute" tolerationSeconds: 3600 --- ##tolerations设置了两个容忍度: ####1、第一个容忍度表示可以容忍restart等于hourly且影响为NoSchedule的污点 ####2、第二个容忍度表示可以容忍isMaintain等于true且影响为NoExecute的污点,tolerationSeconds表示可以容忍污点3600s,如果超过这个时间,Pod将会被驱逐 --- #Pod优先级调度 ###注意:PriorityClass不属于任何命名空间!优先级超过一亿的数字被系统保留,用于指派给系统组件。 --- ##查看PriorityClass kubectl get priorityclass  --- ##创建PriorityClass vim high-priority.yaml =========================================================== apiVersion: scheduling.k8sio/v1beta1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false =========================================================== kubectl apply -f high-priority.yaml --- ##关联PriorityClass apiVersion: v1 kind: pod metadata: name: examplepod spec: containers: - name: examplepod-container image: busybox imagePullPolicy: IfNotPresent command: ['sh','-c] args: ['echo ""hello world";sleep 36000'] priorityClassName: high-priority #关联优先级 --- #容灾调度(Even Pod Spreading调度规则)(1.16版本及以上) apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: topologySpreadConstraints: #容灾调度,均衡分布 - maxSkew: 1 #不均衡数 whenUnsatisfiable: DoNotSchedule topologyKey: topology.kubernetes.io/zone selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.12.2 ports: - containerPort: 80 --- ####maxSkew:用于指定Pod在各个Zone上调度时能容忍的最大不均衡数。(值越大,表示能接受的不均衡调度越大,值越小,表示各个ZONE的Pod数量分布越均匀。) --- ##容灾部署: ####1、将一个应用中需要部署在一起的几个Pod用亲和性调度声明捆绑。 ####2、选择其中一个Pod,加持Even Pod Spreading调度规则。 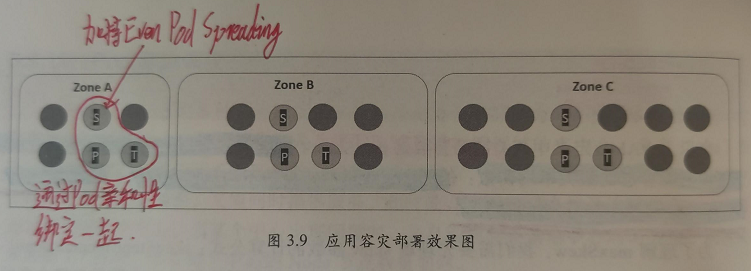
分享到: